Contact us


Analysis: Academic Publications Using Media Cloud
Throughout its existence, the Media Cloud repository of global news and associated analysis tools have consistently been open source, and usage by external researchers has been supported by the Media Cloud team through provision of documentation, training, and technical support. Journalists, activists, and applied researchers are significant and valued user groups of the tooling. Nonetheless, as Media Cloud is engineered to be a research-quality database, academic work using the tool is an important measure of its overall impact. Below we present an analysis of the published academic papers that mention and cite Media Cloud. We did not include teaching materials, white papers, student theses, blog posts, or popular press usages of the tool, which are numerous. Similarly, we did not include publications that only made textual reference to Media Cloud without using it for data or analysis. This analysis yields compelling evidence for the value of Media Cloud to cross-disciplinary academic research, particularly in the fields of public health and political science.
Background
The initial development behind the Media Cloud media repository and analysis tooling began at the Berkman Klein Center for Internet & Society at Harvard University in 2007. The impetus for the project was to examine the influence of blogging on mainstream media coverage by collecting news stories through RSS feeds and running natural language processing tasks on the indexed content. The project continued its development at the MIT Media Lab, with principal investigators at both institutions. Beginning in 2012, a series of foundation grants allowed for further development of the platform, including efforts during 2014-2016 to first develop a public-facing user interface, and subsequently an API. In 2016, the media repository was expanded to ingest media from nearly every country in the world, drawing initially from an external global index, and building depth in key countries through partnerships with journalists and domain experts. In 2020, administration of the project crystallized into a tri-institutional consortium, with principal investigators at University of Massachusetts Amherst, Northeastern University, and nonprofit research organization Media Ecosystems Analysis Group (MEAG). Notably, in 2022, shortly after the index crossed the 1 billion story mark, technology scaling issues necessitated the rebuilding of both the backend index and the frontend user interface. As of 2025, the index is stable with nearly 2 billion stories, and the frontend analysis tool has nearly 6,000 active users.
Volume
We identified 167 academic papers that met our criteria (academic venues, not student work, employing Media Cloud data for analysis) as of November 2025. The first paper found was published in 2011 by the project’s principal investigator at Harvard University, Yochai Benkler. Concurrent with the public user interface being developed in 2014, four papers using Media Cloud were released that year, and four or less were published each subsequent year through 2018. During that time period, approximately half of the papers published were authored by internal Media Cloud researchers, and half were authored by external researchers accessing the tooling.
In 2019 the number of papers published jumped to 10, and in 2020 the number more than doubled, with 24 published papers using Media Cloud that year. This spike in usage (see Figure 1 for a visualization) was concurrent with the Covid-19 pandemic, and a clear application of the Media Cloud tools to research about public health and media coverage.
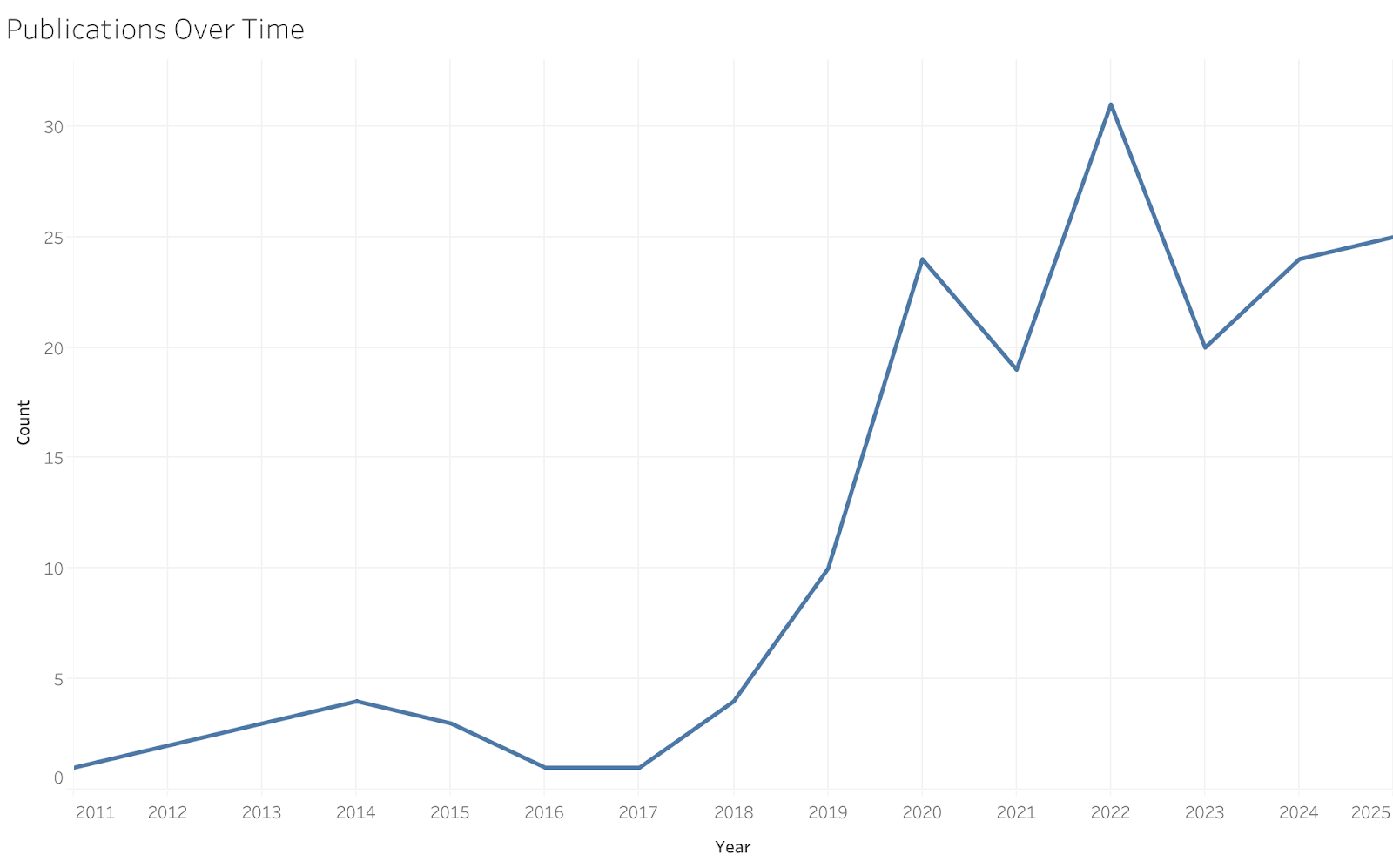
Counts of papers have remained at that level since 2020, with approximately 20-30 publications per year. 2022 saw the highest volume thus far, at 31 papers published. As of mid-November 2025, there have been 25 papers published using Media Cloud in the calendar year.
Topics of Focus
To explore topic distribution, we employed an LLM to assign three classification topic labels to each paper. We manually reviewed each result and selected the best two of the three LLM-suggested labels, refining where needed (e.g., combining the often duplicative “Journalism Studies” and “Communication Studies” into “Media Studies”), and confirming the correct ordering of primary and secondary topics. This process yielded 28 unique topics of focus within the academic paper corpus. Figure 2 visualizes the leading primary topics in the corpus, limiting to only those primary topics with more than three papers.
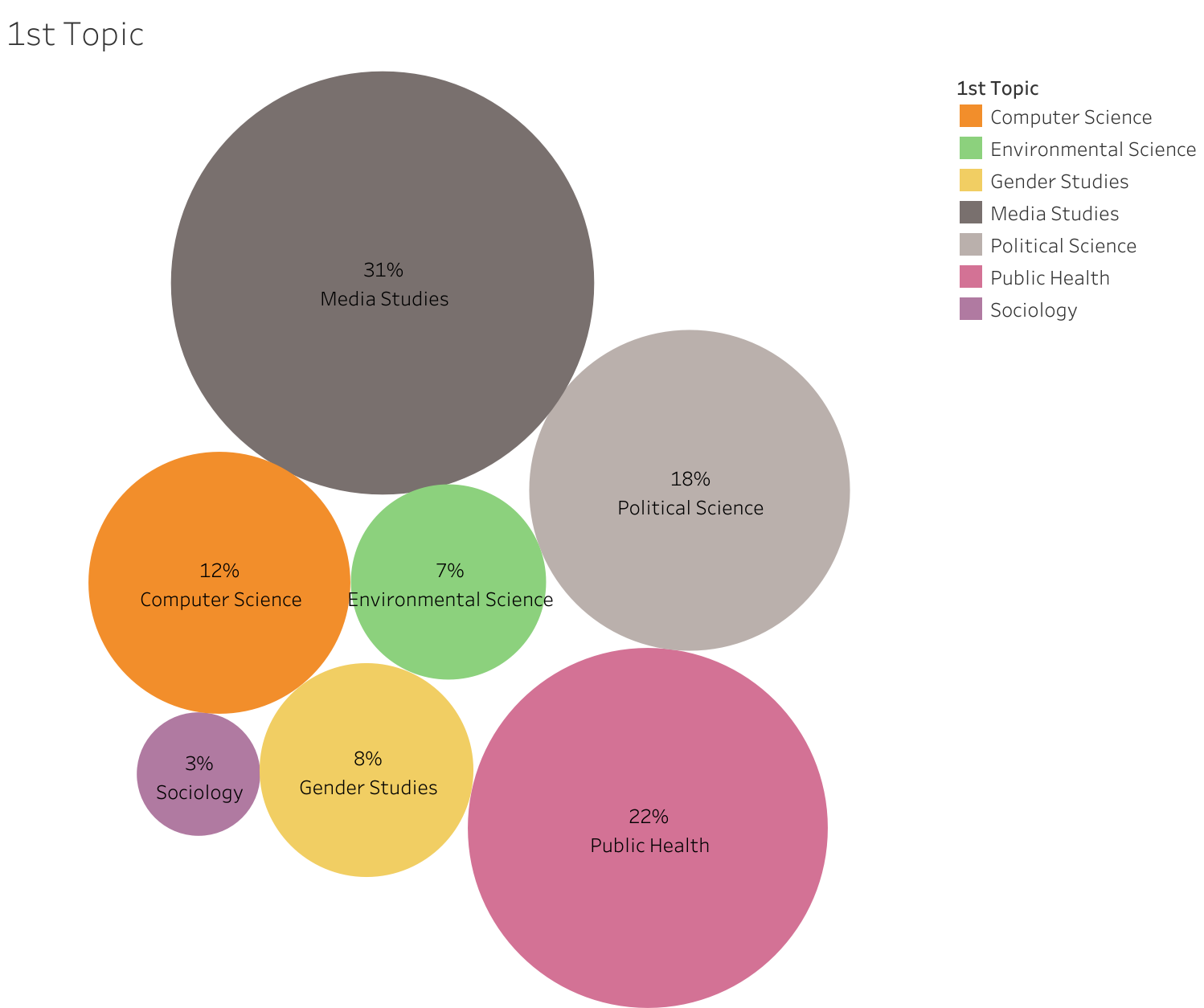
As expected, media studies is the leading primary topic, representing approximately one-third of all papers. Public health is the second most prominent topic, with slightly more than one in five of all papers having it as a primary topic. Political science is third, at nearly one in five focused on the topic. These are followed by computer science, gender studies, environmental science, and lastly, sociology.
Digging further into the most prominent topics (media studies, public health, political science, and computer science), we identified the following key subtopics for research:
- Media studies: news coverage, news narratives, social media, hyperlinking and media ecosystems, news influencers, media bias
- Public Health: Covid-19, substance use, violence, health communication / infodemic, mental health
- Political Science: media partisanship, partisan echochambers, political conspiracy, political violence, campaign messaging, international relations
- Computer Science: artificial intelligence, LLMs, data visualization, event detection, topic analysis, prediction
When looking at the breadth of all topic labels applied, for both primary and secondary topics (see Table 1 below), again media studies is the most frequently applicable topic, followed by public health, political science, and computer science. There is an interesting long tail of topics showing how many domains news analysis can be applied to, including: environmental science, science and technology, computational social science, sociology, youth studies, gender studies, history, African studies, and even more niche applied areas such as tourism studies and food studies.
To explore interesting areas of cross-disciplinary work, we analyzed which primary and secondary topics overlapped most frequently. Public health primary topic with media studies secondary topic was by far the most prominent nexus, with 22 papers in this space; this is further evidence for the importance of Media Cloud in public health research.
Media studies was frequently one of the two topics assigned (approximately 70% of the papers had media studies as either the primary or secondary topic label), which makes sense given the dataset is of news. Outside of media studies, there were clusters of papers in computer science + data science, and in public health + computer science. Both of these demonstrate the use of Media Cloud in building computational pipelines.
Geographies
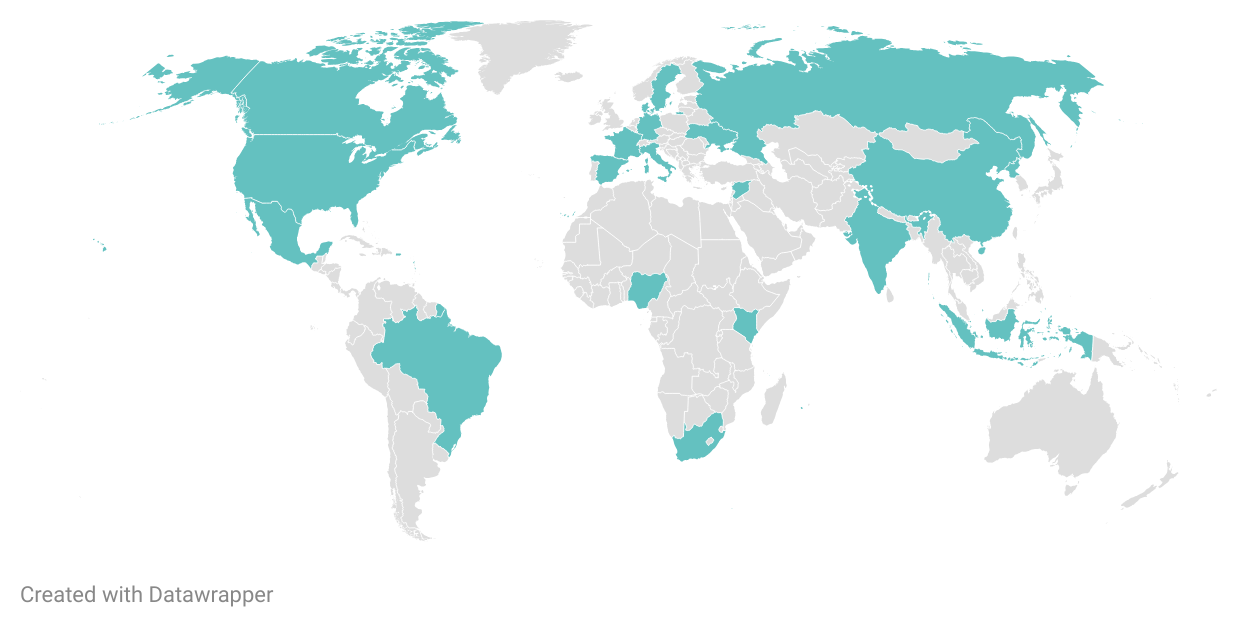
Media Cloud’s global scope allows for studies in nearly any country in the world, and multiple multi-national studies have been published. Studies have been published in multiple languages as well, including English, Italian, and French. The countries mentioned in paper titles, which is not exhaustive of regions studied, is visualized in Figure 3 below. Named regions are not visualized, though “Europe,” “Africa,” and “Latin America” were among the geographies listed in paper titles. The geographic range was quite broad, with every continent represented.
Figure 3. Countries mentioned in titles of papers using Media Cloud
Venues
We identified 122 unique venues of publication. The most prominent publication was the preprint server arXiv, which makes intuitive sense; medRxiv, the medical preprint server, was also present. Outside of these preprint servers, 10 venues had at least three papers that used Media Cloud. These venues are presented in Table 2 below, along with the titles of the papers, to give more detail into research with Media Cloud that made it to publication.
Thirteen venues had two publications using Media Cloud, and 97 venues had only one publication. Venues included journals, preprint servers, and peer-reviewed conference proceedings. This shows the breadth of academic spaces that Media Cloud’s online news archive data has supported, introducing a broad spectrum of academic audiences to its value as a data source and analytic tool.
Conclusion
This overview provides a sense of the wide range of applications of Media Cloud in academic study. Though not presented in depth in this analysis, of note is the additionally wide range of methods employed in papers that use Media Cloud, from deep qualitative analysis of a small number of articles, to complex computational pipelines involving generative AI tools (such as “HEAL-Summ: a lightweight and ethical framework for accessible summarization of health information”). Some researchers need only the metadata provided on news attention, such as count and publication date, while others run scrapers to access full text and run natural language processing methods on their derived corpus. Some papers use only the secondary news data, while others incorporate interviews with journalists, activists, or subjects of stories to investigate framing and impact.
This breadth of academic citations show Media Cloud has established itself as a key piece of digital public infrastructure, including being awarded that designation by the UNDP. This exploration of academic work using Media Cloud demonstrates its breadth and importance to scientific study, which has only increased over years of development and outreach to the research community. We thank our funding partners who have made this possible, including the Gates Foundation, Ford Foundation, Knight Foundation, the Ford Foundation, MacArthur Foundation, and the National Science Foundation.

